
SEO 적용기는 총 2편의 시리즈로 구성되어 있습니다.
- SEO 적용기 #상 (현재글)
- SEO 적용기 #하
들어가며
다음 블로그 포스팅 주제에 대해 고민하고 있었던 차에 파트 내에서 블로그에 SEO 적용할 사람의 지원을 받았습니다. pxd 홈페이지에 SEO를 meta 태그로 설정한 경험이 있어 단순한 생각으로 지원을 하였지만 SEO에 대한 파트 회의에 참여한 후 빈약하고 한정적으로 알고 있었다는 것을 깨닫게 되었습니다. 그래서 블로그에 적용 전 관련 내용을 정리하는 과정이 필요하였습니다.
SEO란?
검색엔진 최적화(Search Engin Optimization)
웹 사이트의 검색엔진에서 검색 결과의 상위에 나올 수 있도록 개선하는 작업
요즘은 무언가를 하기(혹은 알기) 위해 먼저 검색을 하고 주로 검색 결과 첫 번째 페이지에서 결과를 찾으며 정보를 얻습니다. 웹 사이트를 소유하고 있다면 수많은 검색 결과 중에서 내가 올린(혹은 우리 회사에서 올린) 자료가 첫 번째 페이지에 노출되고 여러 웹 페이지에 연결되어 자신의 웹 사이트에 방문자가 늘어나길 바랄 것입니다. 특히 수익성(광고, 홍보)과 연결된 경우에는 더욱더 중요시 될 것이구요. 이렇듯 검색엔진 최적화는 필수적인 작업입니다.
전 세계에 여러 포털 사이트는 각각의 검색엔진을 가지고 있으며 기본적인 요소를 제외하면 각각의 SEO에 대한 전략에 차이점이 있습니다. 따라서 어떤 검색엔진의 최적화를 적용할지 정해야 합니다.
왜 Google SEO를 쓰는가?
-
글로벌 점유율
글로벌 검색엔진 순위에서 볼 수 있듯이 전세계 트래픽의 94 %는 Google 검색 엔진에서 발생합니다.글로벌 검색엔진 순위: StatCounter
국내 검색엔진 순위: INTERNET TREND - 트래픽 증가로 인한 마케팅 효과
사용자의 74%는 검색 결과의 첫 페이지 다음으로 스크롤 하지 않습니다. 즉, 검색 결과 상위에 노출되면 트래픽은 증가하고 비용 없이 효과적인 마케팅을 할 수 있습니다.
이렇듯 국내외 높은 사용률을 나타내는 Google 검색엔진을 기준으로 잡은 후 필요에 따라 다른 검색엔진 최적화를 추가로 적용하고 있습니다.
Google 검색엔진에 대해
Google 검색엔진은 콘텐츠을 크롤링 → 웹 색인 → 사용자에게 해당 콘텐츠를 안내하는 프로세스입니다.
- 크롤링
웹 크롤러라는 소프트웨어를 사용하여 공개된 웹페이지를 발견하고 탐색합니다. 이 크롤러는 여러 링크를 넘나들며 웹페이지에 관한 데이터(글, 링크, 이미지 등)를 Google 서버로 가져옵니다. - 색인(index)
크롤러가 웹페이지를 찾으면 Google 시스템에서는 브라우저와 마찬가지로 해당 페이지의 콘텐츠를 렌더링합니다. 이때 키워드 및 웹사이트 최신 정보에 이르는 주요 신호를 기록하며 검색 색인에서 모든 주요 신호를 추적합니다. -
How Google Search Works
어떻게 Google SEO를 쓸 것인가?
-
<title></title>활용합니다.- 웹 페이지의 주제를 효과적으로 전달하는 제목을 선택 + 간단한 설명
- 각 페이지마다 고유의 제목을 달아야 함
-
heading 태그 사용합니다.
- 주제를 표시하고 콘텐츠의 계층구조를 만들어 문서를 탐색할 수 있어야 함
- 주제성이 모호해질 수 있기 때문에 무분별하게 사용은 지양
-
사이트 계층 구조 구성합니다.
- 도메인과 의미있는 페이지 주소 갖기
👍 https://pxd-fed-blog.web.app/aboutSeo/ 👎 https://pxd-fed-blog.web.app/story01/- 탐색경로 목록 사용
home > portfolio > portfolio detail- 404 페이지 활용
- 탐색 페이지(사이트 맵) 만들기
- robot.txt 활용
-
콘텐츠를 최적화합니다.
- 텍스트가 쉽게 읽히도록 작성
- 주제를 명확하게 구성하고 적절한 양의 콘텐츠 제공
- 전문성을 드러내 사이트의 품질 높이기
- 사용자의 주의를 분산시키는 광고는 표시하지 않기
- 링크 텍스트을 활용하여 웹페이지 탐색에 도움을 줌
-
이미지를 최적화합니다.
- img, picture 태그 사용
- alt 속성으로 대체 텍스트 지원
- 간단한 설명이 내포되어 있는 파일명 지정
-
모바일를 최적화합니다.
- 반응형/ 적응형/ 별도 URL 등 모바일 환경지원
- 반응형일 경우 meta name=“viewport” 태그를 사용하여 브라우저 콘텐츠 조정을 알림
- 적응형/ 별도 URL일 경우에도 리소스를 크롤링할 수 있는 상태로 유지
- 모든 기능을 모든 기기에서 동일하게 제공
pxd FED blog에 어떻게 적용할 것인가?
먼저 위 항목 중 블로그에 공통요소로 적용할 수 있는 항목을 추려 정리하였습니다. (이미 블로그에 적용되었거나 추가적으로 보완하지 않아도 되는 요소는 체크해 소거하였습니다.)
- 도메인 생성
- 제목 태그
- 탐색경로 목록
- 사이트 맵
- robot.txt
- meta 태그
사이트 맵
웹 페이지에 목차에 해당합니다.
따라서 사이트 맵이 있는 경우 크롤러는 사이트 맵을 읽어 콘텐츠 관계에 관한 정보를 얻습니다. 최근에 생성 또는 수정된 정보 등 페이지만을 크롤링 할 때 보다 더 자세한 정보를 얻을 수 있으며 크롤링 속도도 개선할 수 있습니다.
파일을 직접 만들 수 있지만 Google에서 제공하는 Search Console를 통해 사이트맵을 제출할 수 있으며 관리하는데도 용이합니다.
Robot.txt
크롤러의 접근을 제어하는 파일입니다.
즉 웹 페이지에서 크롤링할 수 있는 것과 없는 것을 설정할 수 있습니다. 이 설정에 따라 크롤링과 색인에 영향을 주기 때문에 설정법을 잘 숙지한 후 적용하는 것이 중요합니다.
meta 태그
html의 <head></head> 섹션에 추가
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<meta name="robots" content="index, follow" />
<meta
name="description"
content="웹페이지에 대한 명확하고 정확한 설명을 기입합니다."
/>
</head>
</html>
meta 태그 속성
- description
<meta name="description" content="A description of the page" />웹 페이지에 설명을 제공합니다.
내용이 페이지 콘텐츠에서 가져올 수 있는 내용보다 더 정확한 설명을 사용자에게 제공한다고 판단되는 경우, 이를 검색결과 스니펫(미리보기)으로 생성되기도 합니다. 따라서 내용을 간결하고 적절하게 요약하여 사용자에게 찾던 정보를 제공하거나 흥미를 유발하여 클릭을 유도할 수 있어야 합니다. 길이의 제한은 없지만 검색결과 스니펫은 주로 기기 폭에 맞춰 잘려 표시되는 것을 참고하여 작성합니다.
pxd 홈페이지의 검색 결과를 보면 페이지 별로 소개가 노출 되고 있습니다. 이는 페이지마다 각각의 description이 적용되어 있는데 그 내용이 스니펫으로 생성 되었습니다.
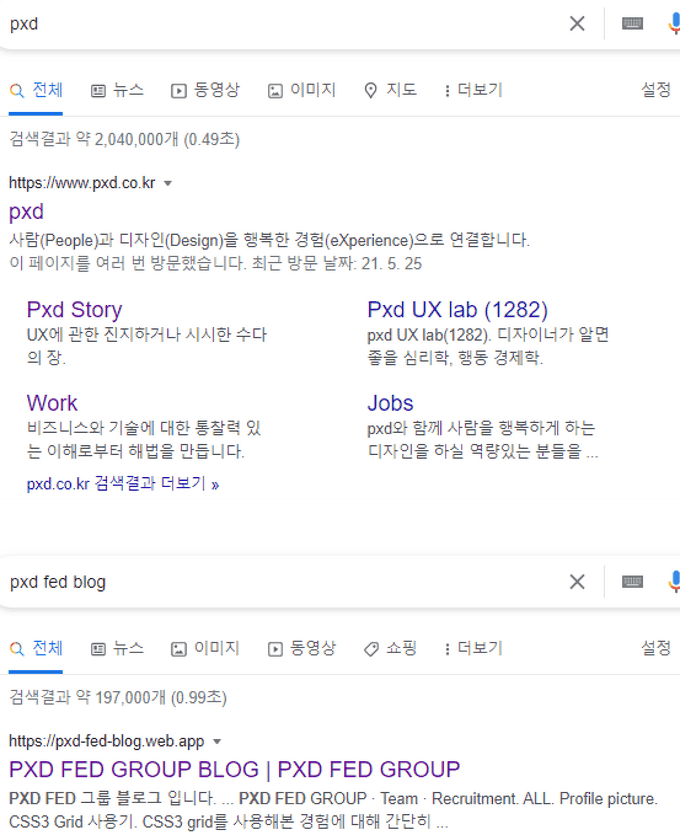
- robots
<meta name="robots" content="index, follow" />검색엔진의 크롤링 및 색인 생성 동작을 제어합니다.
index ↔ noindex
웹 페이지를 크롤링하여 색인을 생성하고 검색결과에 표시 / 크롤링하지 않으며 검색결과에 비표시
follow ↔ nofollow
웹 페이지와 링크된 페이지를 따라가며 링크된 페이지를 크롤링 할 수 있음/ 링크를 따라가지 않음
all
기본값, 명시적 표시, 값에 의미가 없음
none
noindex, nofollow를 의미
noarchive
검색결과에서 “저장된 페이지”에 표시되지 않음
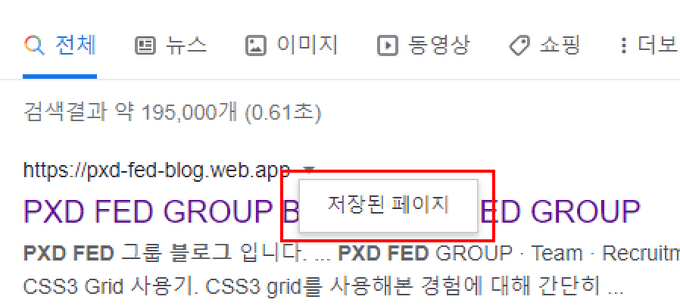
notranslate
검색결과에 페이지에 대한 번역 기능을 제공하지 않음
noimageindex
웹 페이지의 이미지에 대한 색인을 생성하지 않음
nosnippet
검색결과에서 스니펫을 지원하지 않음
max-snippet: [number] 검색결과의 스니펫의 텍스트의 최대 길이를 지정할 수 있음
<!-- 0: nosnippet와 같음 -->
<meta name="robots" content="max-snippet:0" />
<!-- 최대 20자(영문 기준) -->
<meta name="robots" content="max-snippet:20" />
<!-- 내용, 기기 별로 가장 효과적인 스니펫 길이로 노출됨 -->
<meta name="robots" content="max-snippet:-1" />robots.txt와 meta robots의 차이점
robots.txt: 크롤러를 제어하는 경우에 적합
meta robots: 개별 HTML 페이지를 제어할 때 사용함
- SNS
<!-- Facebook -->
<meta property="og:type" content="Blog" />
<meta property="og:title" content="A title of the page" />
<meta property="og:description" content="A description of the page" />
<meta property="og:url" content="https://pxd-fed-blog.web.app" />
<meta property="og:image" content="thumbnail" />
<!-- Twitter -->
<meta name="twitter:card" content="summary" />
<!-- twitter card contnet는 summary_large_image, summary, photo 중 하나를 선택 -->
<meta name="twitter:title" content="A title of the page" />
<meta name="twitter:description" content="A description of the page" />
<meta name="twitter:url" content="https://pxd-fed-blog.web.app" />
<meta name="twitter:image" content="thumbnail" />웹 사이트를 SNS 공유할 때 미리보기에 노출되는 정보입니다.
Facebook과 Twitter에서 제공하며 국내 네이버와 카카오에서도 사용하고 있기 때문에 적용이 필요한 요소입니다. 콘텐츠가 공유되었을 때 미리보기를 통해 클릭(탭) 여부가 결정되기 때문에 흥미를 유발하거나 정보를 충족시킬 수 있는 콘텐츠로 설정해야 합니다.
마치며
내용을 정리하면서 느낀 사항은
- 검색엔진은 동적이고 유기적인 똑똑한 알고리즘이다.
- 웹표준을 준수하는 것만으로도 SEO의 기본은 적용할 수 있다.
입니다. 또한 웹 사이트의 목적과 범위 등을 파악하여 웹표준과 meta 태그를 사용하여 기본적인 수준으로 적용할 것인지, 사이트맵과 robots.txt를 통해 좀 더 철저하고 유기적으로 적용할 것인지 살펴볼 수 있었습니다.
블로그의 SEO 적용은 다음 블로그에 SEO 적용하기 #2에서 포스팅할 예정입니다.
고맙습니다. - 끄읕 -